
cat _posts/ru/2019-04-22-upx-ru.md
22 April 2019Распаковка UPX вручную
Для примера возьмем любой файл и запакуем его с помощью UPX. Скачиваем с сайта упаковщик и запаковываем.
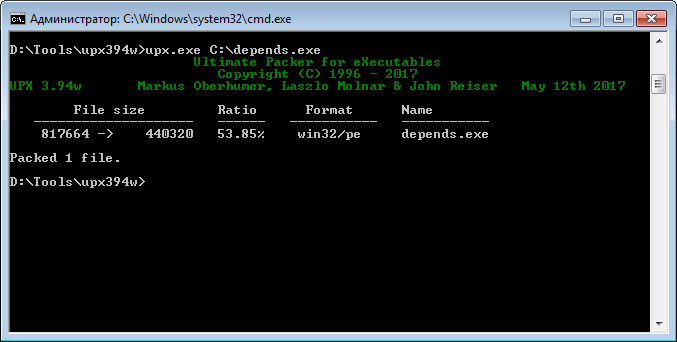
Убедимся, что файл запакован. Сделать это можно несколькими способами.
1) С помощью программы Detect it easy!
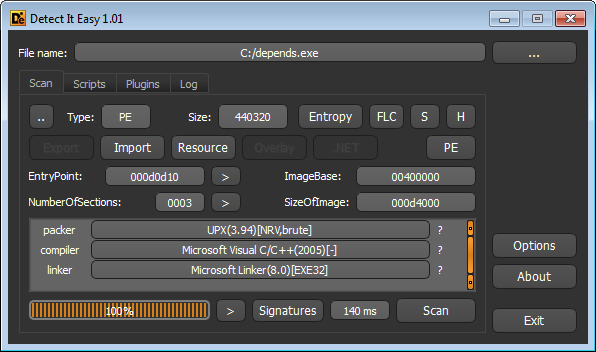
Как мы видим, он показывает, что файл упакован UPX(3.94)
2) С помощью PEid
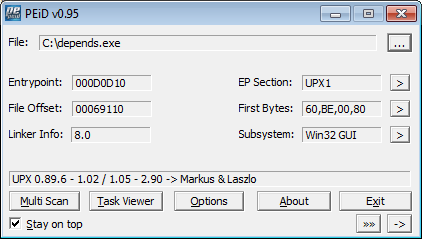
Здесь тоже видим UPX.
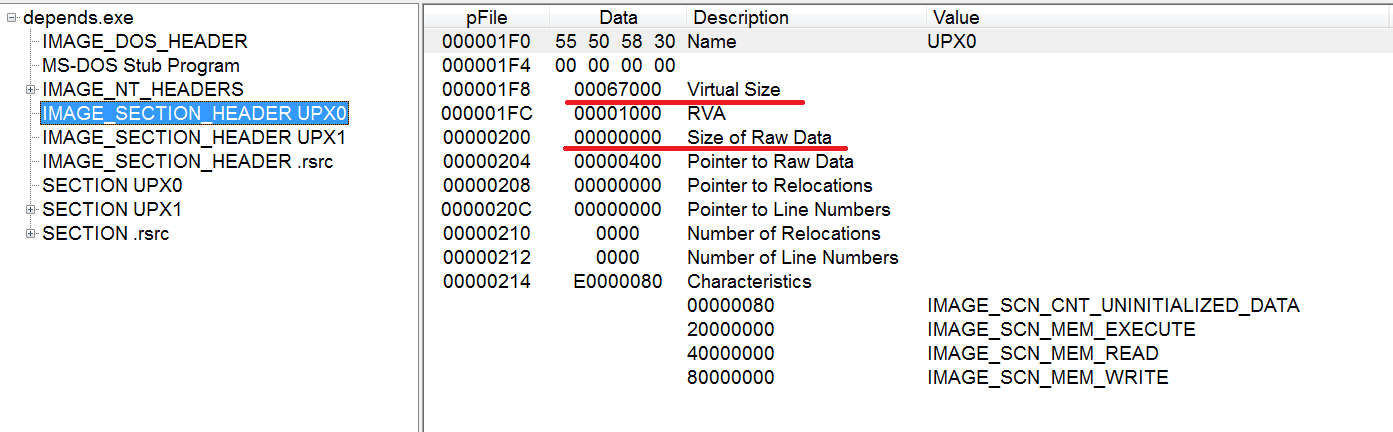
3) С помощью PEView. PEView дает информацию о PE Header, из который мы можем увидеть, что бинарь содержит секции UPX.
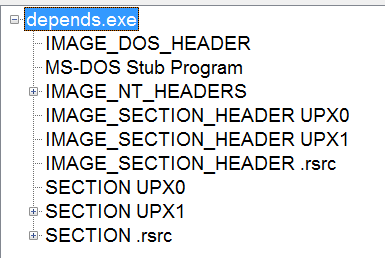
Еще один способ понять, что что-то не так с файлом, это разница между значениями SizeOfRawData (размер данных на диске) и VirtualSize (количество памяти, которое надо выделить для секции). Например, у секции UPX0, SizeOfRawData равен 0, что уже ненормально, а VirtualSize = 67000, что говорит нам о том, что в секции заполняется данными во время выполнения.
4) Если открыть файл в IDA, то получим следующее сообщение:
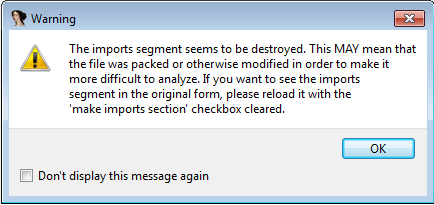
IDA сообщает нам, что она не смогла определить стандартные секции в файле (.text, .data, …)
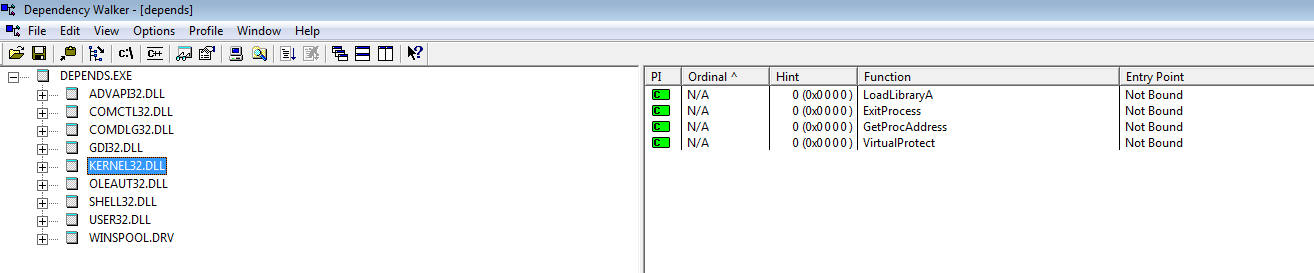
5) Посмотрев таблицу импорта, с помощью Dependency walker, мы видим только функции LodaLibrary, GetProcAddress. Такой набор функций говорит о том, что таблица импорта восстанавливается во время выполнение. Вручную загружается каждая библиотека (LoadLibrary) и достаются адреса каждой функции (GetProcAddress)
Мы определили, что файл запакован, теперь попробуем распаковать его вручную, с помощью IDA. Чтобы распаковать файл, нам необходимо сделать 3 вещи: 1) Отдебажить до того момента, когда данные распакуются 2) Разрезолвить таблицу импорта 3) Поменять OEP (Original Entry Point) на изначальный
Открываем файл в IDA поставив галочку на "Manual load" и убрав с "Create imports segment" (If checked, IDA will convert .idata section definitions to "extrn" directives and truncate it).
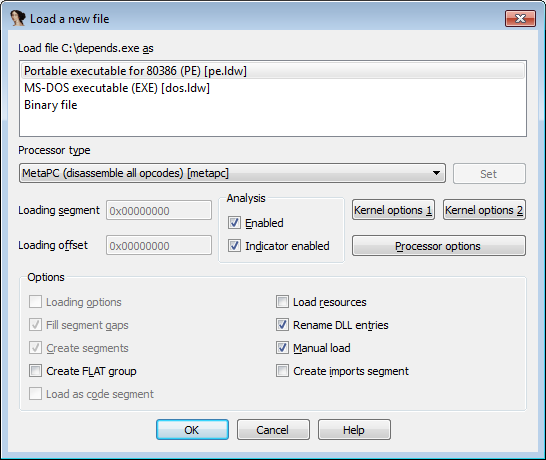
Далее нас попросят указать Image Base (его можно посмотреть, с помощью PEView, в IMAGE_OPTIONAL_HEADER), загружаем все секции. Теперь наша задача найти, когда выполняется инструкция PUSHA/PUSHAD (Поместить в стек значения всех 32-битных регистров общего назначения ). Запускаем, ищем, ставим брейкпоинт на PUSHAD.
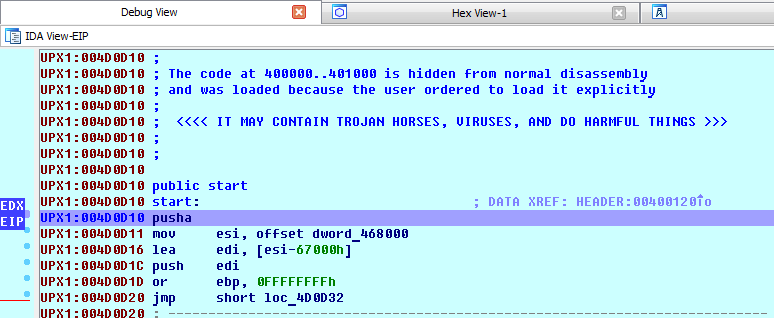
С этой инструкции начинается процесс распаковки UPX, поэтому все значения регистров сохраняются. Соответственно, после распаковки должна быть выполнена инструкция POPA, которая восстановит прежние значения. На нее мы и должны поставить брейкпоинт. Сделать это можно двумя способами. 1) Text search по слову POPA, ставим брейкпоинт, продолжаем выполнение до срабатывания.
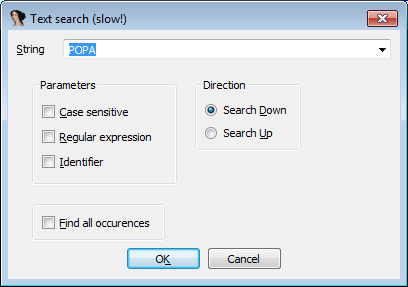
2) Выполняем инструкцию PUSHA (то есть EIP стоит на строке после PUSHA). Переходим на адрес ESP, с помощью нажатия стрелочки напротив ESP в списке регистров.
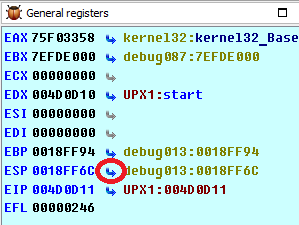
Ставим Hardware on write брейкпоинт размером 4 байта. Как альтернатива, можно также поставить брейкпоинт на адрес ESP + 4. Не забудь убрать брейкпоинт, после его срабатывания. Смысл в том, что ты ставишь брейкпоинт на ESP до распаковки. Когда все распакуется, ESP вернется к прежнему значению и выполнится POPA и сработает брейкпоинт.
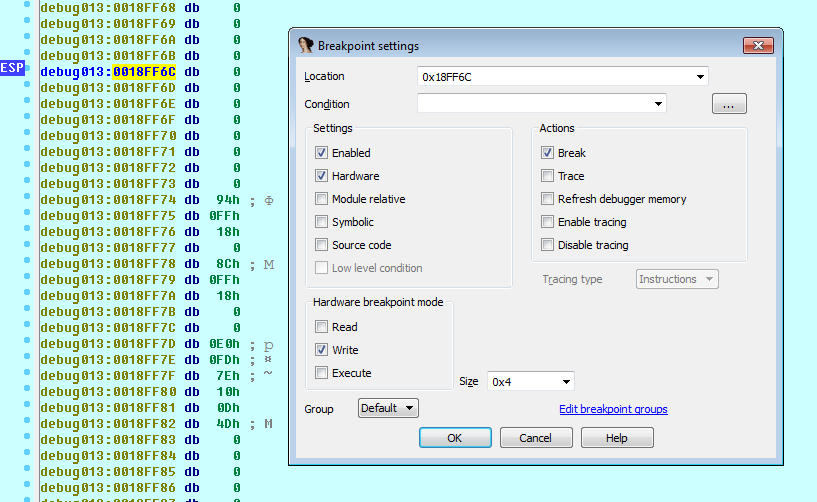
После срабатывания брейкпонта на POPA, где-то рядом, дальше мы должны увидеть TAIL JMP.
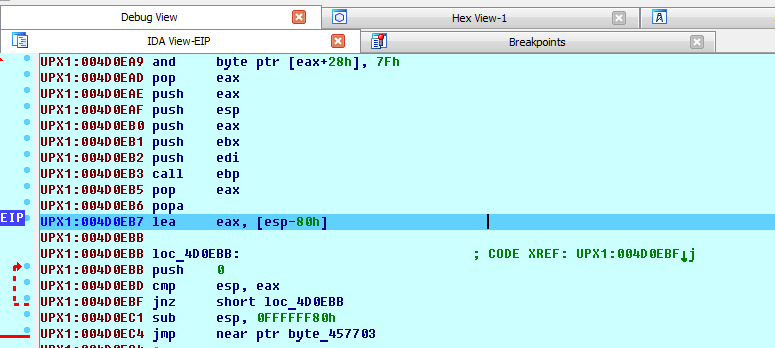
TAIL JMP - инструкция, которая перенаправляет выполнение на OEP. Характерной особеностью адреса, по которому совершается переход, является его отдаленность, от текущего адреса. Это происходит, потому что данные распаковываются в секции UPX1 и помещаются в UPX0. Понять, что распаковка происходит в секцию UPX0 можно было по его свойствам SizeOfRawData=0 и VirtualSize. Плагины для дебаггеров, которые определяют OEP полагаются на это свойство перехода и определяют, когда выполнение в одной секции переходит на выполнение в другой. Выполняем инструкцию jmp.
Всё, теперь мы находимся на OEP, а значит надо сделать дамп распакованной в памяти программы. Делаем это, с помощью Lord PE. Запускаем LordPE, находим процесс, делаем dump full.
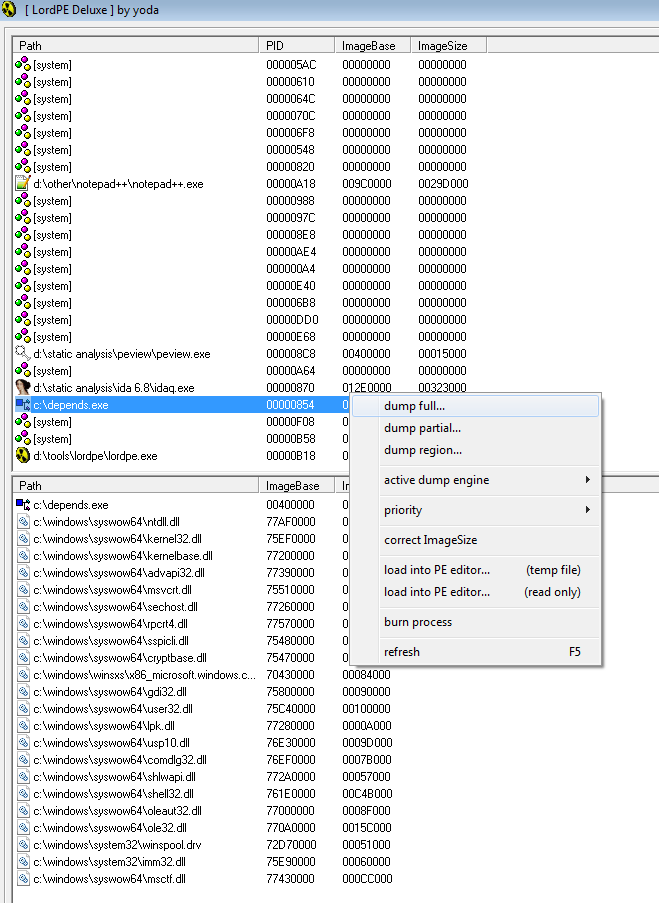
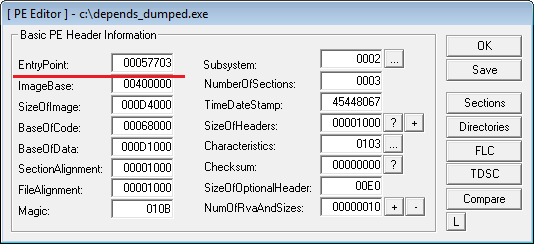
Открываем дамп в PE Editor (LordPE) и прописываем OEP, он у нас равен 57703 (RVA). Это адрес мы видим, после перехода по Tail JMP. Сохраняем.
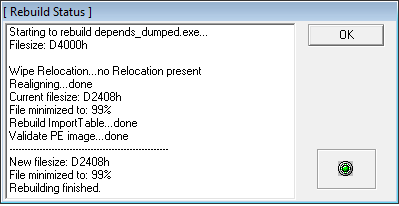
Открываем дамп в Rebuild PE (Lord PE), чтобы подправить выравнивания и т.д.
Запускаем дамп, открываем ImpRec, чтобы подправить таблицу импорта. В ImpRec выбираем процесс дампа, нажимаем “IAT AutoSearch”, “Fix Dump”. Всё, можно сравнить таблицу импорта оригинального файла и полученного.