
cat _posts/ru/2020-08-20-malware-identifying.md
20 August 2020Два простых способа идентификации неизвестной малвари
Intro
Перед изучением неизвестного вредоносного файла, обычно пытаются выяснить
- Является ли малварь уже известной сообществу (проанализированной)
- Принадлежность к определенному семейству (вариант известного RAT/бэкдора)
- Принадлежность к конкретной APT группе
Для этого, вычисляется хэш файла и производится поиск по общедоступным базам (virustotal, totalhash, virusshare, virusbay, …). Поиск может не дать результатов по причинам:
-
Не все сэмплы загружаются в общедоступные базы. Бывают ситуации, когда антивирусным компаниям/исследователям сливать файл нельзя - разработчикам малвари будет известно, что их обнаружили. Они могут распространять разные версии малвари для разных регионов/организаций и увидев в публичном доступе свой файл, понять конкретное место утечки
-
Разработчики малвари могут билдить варианты одной программы, с разными ip, набором ресурсов, payload, текстом на разных языках (в случае шифровальщиков), адреса btc кошельков и т.д. В этом случае, несмотря на то, что малварь по сути одна и та же, хэш будет отличаться.
Помочь обойти эти препятствия на пути идентификации неизвестного сэмпла помогут два способа - imphash и fuzzyhash.
imphash
imphash - это хэш, который вычисляется от списка импортируемых функций в PE файле. Пример импортируемых функций в PE файле:
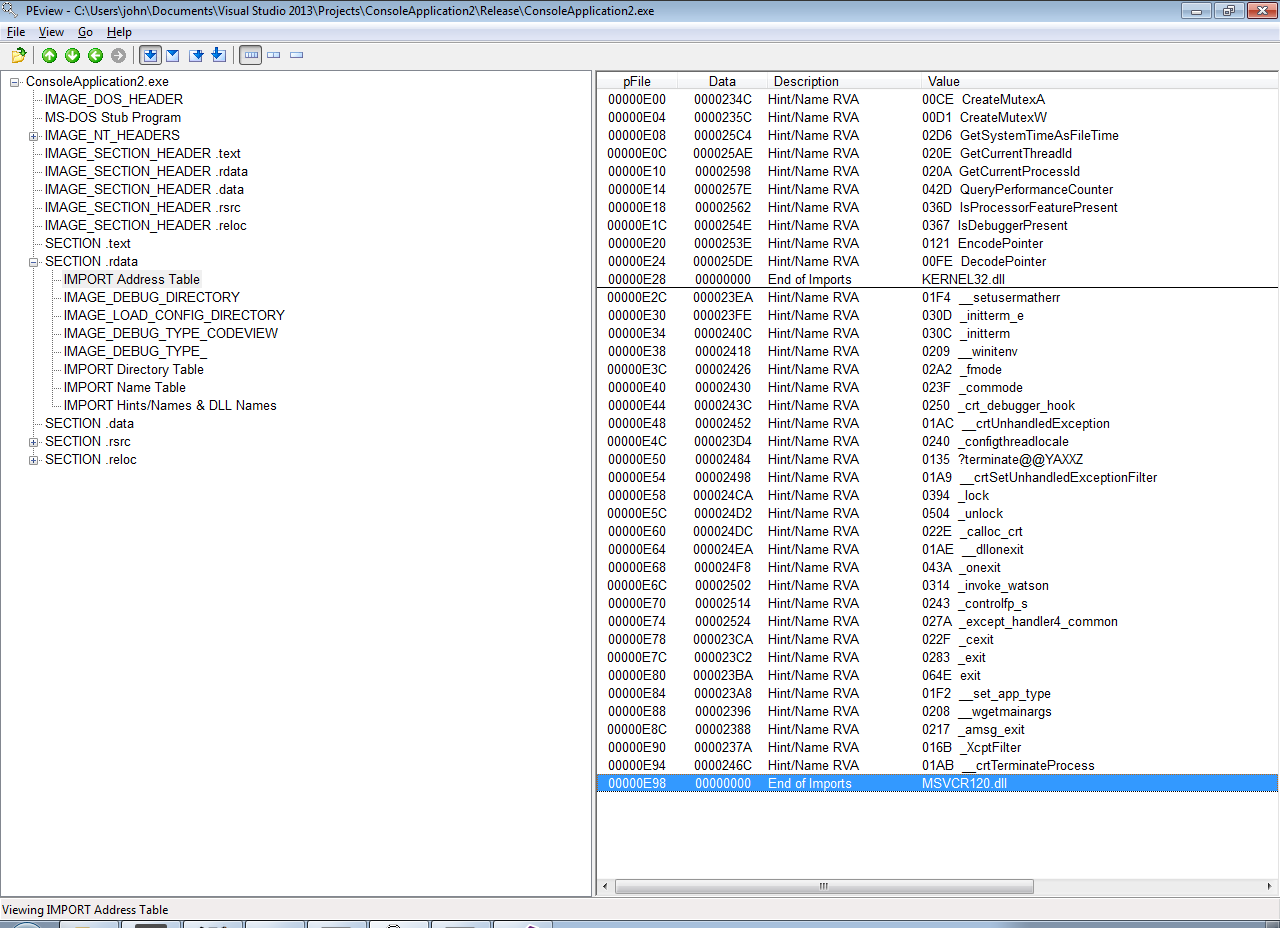
Официальная документация PE формата
Более расширенное описание PE формата: 1 часть, 2 часть
Впервые, метод был описан в отчете от FireEye в 2014 году
Данный вид хэша решает две проблемы, описанные ранее:
- Практически все общедоступные базы малвари прикладывают значение imphash. Поэтому вы можете найти связанные сэмплы поиском по imphash, не выдавая свой:
Анонс Virustotal о вводе imphash в своей базе
Пример поиска по imphash на Virusshare:
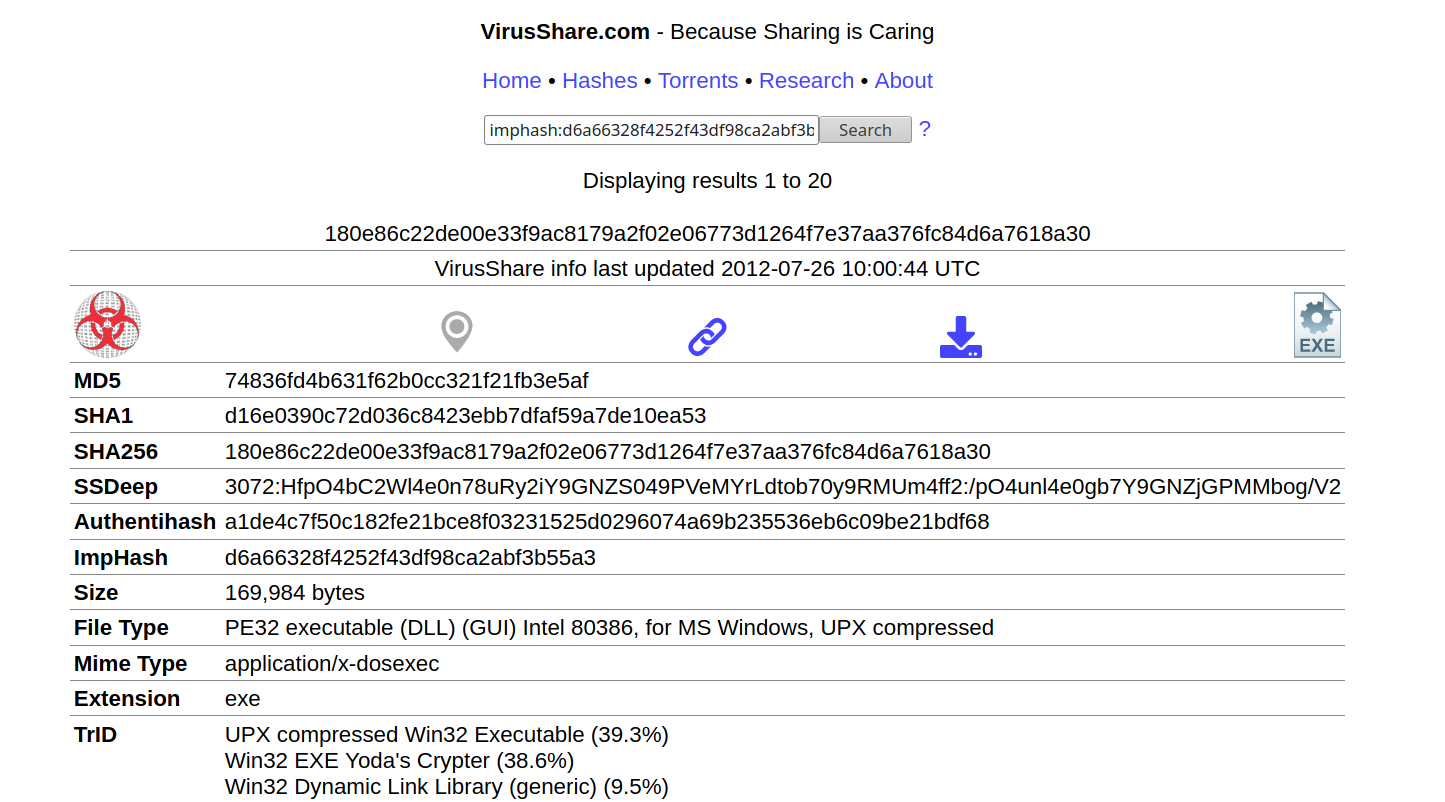
- Каждый новый вариант малвари может содержать новые ip адреса, секции, ресурсы и т.д., но набор используемых функций будет неизменен
imphash может быть использован для сканирования системы на наличие подозрительных файлов. Скриптом ImpHash-Generator можно создать базу хэшей “хороших” файлов в начальном состоянии ОС.
Авторы идеи imphash закоммитили патч, с алгоритмом вычисления, для популярного инструмента, для анализа PE файлов - pefile.
Алгоритм вычисления imphash:
#DIRECTORY_ENTRY_IMPORT (list of ImportDescData instances)
def get_imphash(self):
impstrs = []
exts = ['ocx', 'sys', 'dll']
if not hasattr(self, "DIRECTORY_ENTRY_IMPORT"):
return ""
for entry in self.DIRECTORY_ENTRY_IMPORT:
if isinstance(entry.dll, bytes):
libname = entry.dll.decode().lower()
else:
libname = entry.dll.lower()
parts = libname.rsplit('.', 1)
if len(parts) > 1 and parts[1] in exts:
libname = parts[0]
for imp in entry.imports:
funcname = None
if not imp.name:
funcname = ordlookup.ordLookup(entry.dll.lower(), imp.ordinal, make_name=True)
if not funcname:
raise Exception("Unable to look up ordinal %s:%04x" % (entry.dll, imp.ordinal))
else:
funcname = imp.name
if not funcname:
continue
if isinstance(funcname, bytes):
funcname = funcname.decode()
impstrs.append('%s.%s' % (libname.lower(),funcname.lower()))
return md5( ','.join( impstrs ).encode() ).hexdigest()
Алгоритм:
- Парсинг Import Directory Table
- Создание списка из элементов вида “имя_библиотеки.имя_функции”
- Вычисление md5 хэш списка
Наглядно, результат можно увидеть на примере сэмпла, который я скачал с сайта vx-underground, под названием Backdoor.Win32.Agent.vuz.08248dd1e494f0cd7370067f430b3492. Вот так выглядит его таблица адресов импортируемых функций (IAT):
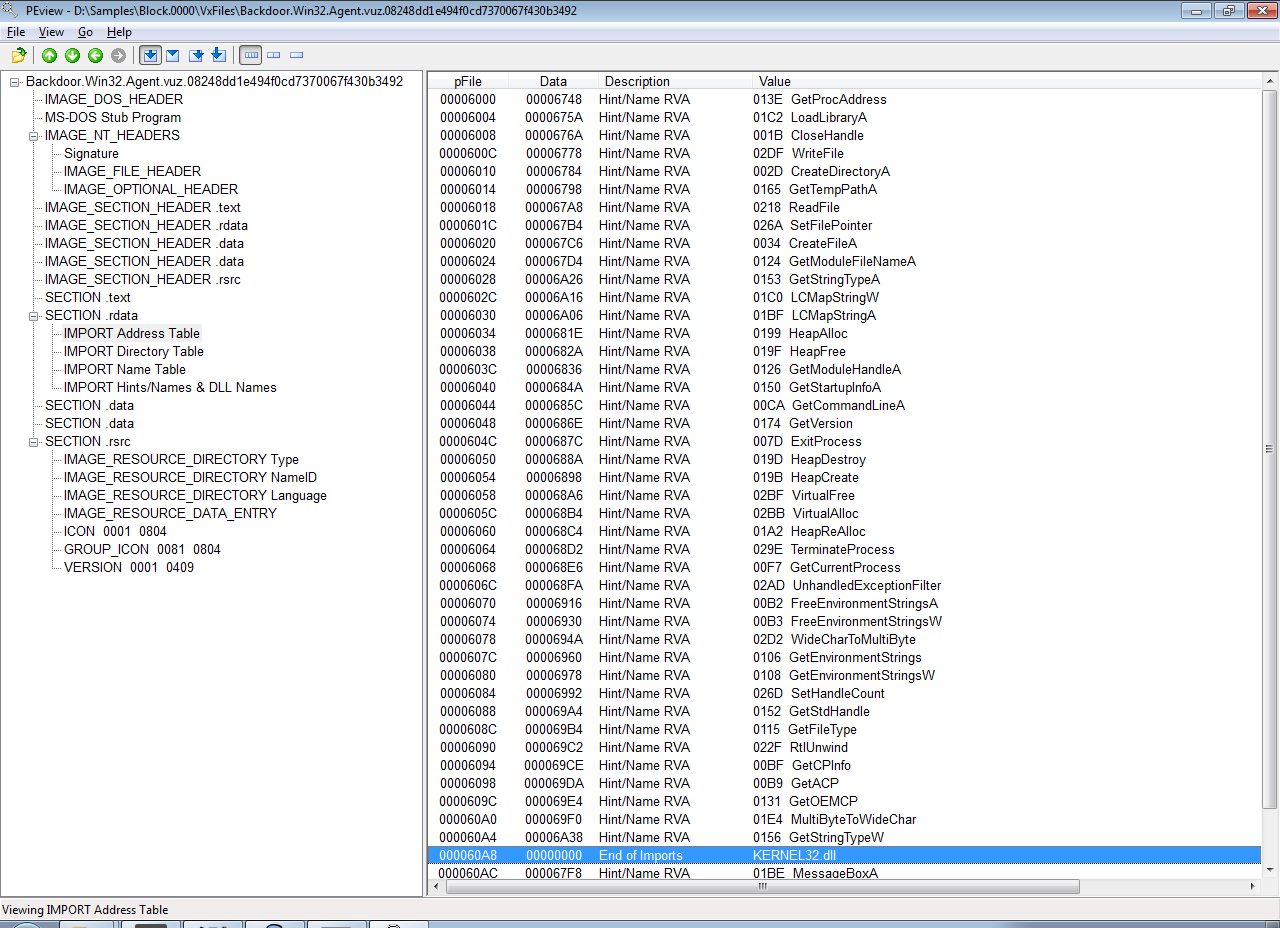
imphash в этом случае будет вычислен от следующей строки, которая является конкатенацией имен функций:
kernel32.getprocaddress,kernel32.loadlibrarya,kernel32.closehandle,kernel32.writefile,kernel32.createdirectorya,kernel32.gettemppatha,kernel32.readfile,kernel32.setfilepointer,kernel32.createfilea,kernel32.getmodulefilenamea,kernel32.getstringtypea,kernel32.lcmapstringw,kernel32.lcmapstringa,kernel32.heapalloc,kernel32.heapfree,kernel32.getmodulehandlea,kernel32.getstartupinfoa,kernel32.getcommandlinea,kernel32.getversion,kernel32.exitprocess,kernel32.heapdestroy,kernel32.heapcreate,kernel32.virtualfree,kernel32.virtualalloc,kernel32.heaprealloc,kernel32.terminateprocess,kernel32.getcurrentprocess,kernel32.unhandledexceptionfilter,kernel32.freeenvironmentstringsa,kernel32.freeenvironmentstringsw,kernel32.widechartomultibyte,kernel32.getenvironmentstrings,kernel32.getenvironmentstringsw,kernel32.sethandlecount,kernel32.getstdhandle,kernel32.getfiletype,kernel32.rtlunwind,kernel32.getcpinfo,kernel32.getacp,kernel32.getoemcp,kernel32.multibytetowidechar,kernel32.getstringtypew,user32.messageboxa,user32.wsprintfa
Вы можете возразить, что идентификация упакованной малвари будет бесполезна, так как пакеры часто используют один и тот же набор функций (VirtualAlloc, GetProcAddress, LoadLibrary, …). Предполагается, что анализ проводится над уже распакованным/сдампленым сэмплом.
Минусы идентификации по imphash:
- Много false positive. Одни и те же API могут использоваться в никак не связанных между собой программах
- Маленькая точность. Даже небольшое изменение списка функций координально изменяет хэш
Поэтому способ годится больше для первоначального анализа и получения списка сэмплов, которые требуют более пристального внимания.
В отличие от обычных PE программ, .NET программы импортируют только одну библиотеку “mscoree.dll”, поэтому imphash к ним неприменим. Зато у .NET программ есть Metadata table. Metadata table содержит все используемые программой типы и неймспейсы. Их можно использовать для хэширования, вместо таблицы импортов классического PE файла. Такой хэш назвали TypeRefHash.
В отличие от PE, у Mach-O файлов (формат в MacOS) совершенно другая структура. Поэтому для него придумали SymHash (аналог imphash).
Скрипт, для вычисления SymHash
Для ELF файлов существует несколько разных модификаций алгоритма вычисления хэша импортируемых функций. Одним из самых лучших на мой взгляд, является реализация от Trend Micro - Trend Micro ELF Hash. Они используют комбинированный подход с fuzzy hash (об этом позже).
Инструмент для вычисления аналога imphash для ELF на GO номер 1
Предотвращение идентификации по imphash
Первый - это вызов и получение функций в рантайме, с помощью LoadLibrary/GetProcAddress. Таким образом список импортируемых функций будет похожим на списки огромного количества других программ.
Второй - вручную менять порядок определений/вызовы функций в исходном коде или менять очередность передачи файлов компилятору. Если вы обратите внимание на оригинальный алгоритм, то в нем нет сортировки списка перед хэширование, из-за этого и появился такой способ обхода. К сожалению, изначальный алгоритм из скрипта pefile стал каноном и используется повсеместно (от всех известных инструментов до баз с малварью).
Способ обхода подробно описан в статье Tracking Malware with Import Hashing
Модифицированный скрипт, который сортирует
В статье “Tracking Malware with Import Hashing” утверждается, что функции, в таблице импортов PE файла, располагаются в том порядке, в котором они появляются в исходном коде. Я проверил и оказалось, что это справедливо только для программ, скомпилированных и слинкованных visual c++ build tools версий меньше 2013 (включительно). Если вы попытаетесь сделать то же самое, используя более новые build tools, то у вас ничего не получится. Поэтому этот способ я считаю устаревшим.
Третий - изменение таблицы импортов в уже скомпилированной программе. Алгоритм следующий (псевдокод):
thunk_data = [] # vector of (orig_thunk.addressofdata, thunk)
thunk_data_copy = [] # holds duplicate of thunk_data
original_to_new = {} # map<firstthunk, firstthunk>
for entry in DIRECTORY_ENTRY_IMPORT:
for import in entry.imports:
thunk_data.append((import.original_thunk.addressofdata,
import.firstthunk))
thunk_data_copy = thunk_data.clone()
random_shuffle(thunk_data)
for i in range(thunk_data.length):
original_to_new[thunk_data[i].second] = thunk_data_copy[i].second
for entry in DIRECTORY_ENTRY_IMPORT:
i = 0
for import in entry.imports:
import.original_thunk.addressofdata =
import.firstthunk.addressofdata = thunk_data[i].first
i = i+1
for relocation_block in DIRECTORY_ENTRY_BASERELOC:
for patch_address in relocation_block:
lookup = patch_address - imagebase
value = original_to_new.find(lookup)
if value:
relocation_block[patch_address] = value + imagebase
Алгоритм:
- Парсинг Import Directory Table
- Создание списка из элементов вида “OriginalFirstThunk + FirstThunk”
- Рандомное перемешивание списка
- Обновление таблицы импортов новыми значениями из списка
- Обновление relocation структур
Преимущества алгоритма - не требуется перекомпиляция/перелинковка оригинальной программы, функционал остается прежним.
fuzzyhash
fuzzyhash (или по другому Context triggered piecewise hashes (CTPH))- алгоритм выявления похожих файлов. Алгоритм сравнивает хэши разных последовательностей байт двух файлов и выдает процент схожести между всеми последовательностями. Алгоритм, изначально, был не был нацелен на идентификацию малвари, но исследователи малвари увидели в нем потенциал для своих задач. Таким образом его можно использовать, для выявления разных модификаций одной и той же малвари.
Интервью с чуваком, который использовал fuzzyhash для малвари
Изначальный алгоритм, использовавшийся в утилите dcfldd, хэшировал файл кусками фиксированной длины. Например, брали первые 512 байт файла, хэшировали, потом следующие 512 байт и так далее. Также поступаем и со сравниваемым файлом. Далее сравниваем эти два массива хэшей (фазим) и получаем процент схожести двух файлов. Такой способ называется хэшированием по кускам (Piecewise hashing).
Потом, этот алгоритм улучшили, и начали хэшировать не фиксированными кусками, а проходясь по изменяющимся последовательностям байтов с конца файла (rolling hashing). Этот улучшенный алгоритм и назвали fuzzyhash.
Об этом всем подробно читайте в исследовании Identifying almost identical files using context triggered piecewise hashing
Я взял 80 гигабайт сэмплов малвари с сайта vx-underground и сделал сравнение по fuzzyhash, программой ssdeep. Сэмплы с этого сайта хороши тем, что они правильно проименованы.
Часть результата, в скобках процент схожести:
Backdoor.Win32.Agent.bkn.4d956a843fa431b608f426e15fb69520 matches Backdoor.Win32.Agent.bkn.026e279f2c16d654e17f6fb5c45e1741 (57)
Backdoor.Win32.Agent.bkoh.6a612dc284ef8d7f38304680a0e28693 matches Backdoor.Win32.Agent.bjup.961014b078122e628dbef050e58c9cd0 (99)
Backdoor.Win32.Agent.bkpe.f777700b6dfd3e11a808f81fdd494fb3 matches Backdoor.Win32.Agent.bjup.961014b078122e628dbef050e58c9cd0 (96)
Backdoor.Win32.Agent.bkpe.f777700b6dfd3e11a808f81fdd494fb3 matches Backdoor.Win32.Agent.bkoh.6a612dc284ef8d7f38304680a0e28693 (96)
Backdoor.Win32.Agent.bkqk.dafedf9521d55dbe25c68f3fcc9f970d matches Backdoor.Win32.Agent.bjup.961014b078122e628dbef050e58c9cd0 (97)
Backdoor.Win32.Agent.bkqk.dafedf9521d55dbe25c68f3fcc9f970d matches Backdoor.Win32.Agent.bkoh.6a612dc284ef8d7f38304680a0e28693 (97)
Backdoor.Win32.Agent.bkqk.dafedf9521d55dbe25c68f3fcc9f970d matches Backdoor.Win32.Agent.bkpe.f777700b6dfd3e11a808f81fdd494fb3 (96)
Backdoor.Win32.Agent.lei.08305b81ebfe3cfe37bcb1ec5e05531d matches Backdoor.Win32.Agent.hmv.845f009f63a39c2526ea8caba15c94a4 (55)
Backdoor.Win32.Agent.tyx.dcee8fe38cb66cefbb1cbee3f35b8107 matches Backdoor.Win32.Agent.qgq.734c8a4e104990bd785b1dc4ade1d5ac (61)
Backdoor.Win32.Agent.ucs.3dd15d055bb58c47ad6d48fa2009dca9 matches Backdoor.Win32.Agent.bkk.c29bc042c29b26ba7b43e035069cc673 (38)
Backdoor.Win32.Agent.ucv.d79281a60f0429c1846372a28084cfd0 matches Backdoor.Win32.Agent.ucq.5bee36b9e85e3d6afd5babf809eb4c9e (99)
Как видите, с помощью fuzzyhash, удалось определить схожие сэмплы, с разными хэшами.
impfuzzyhash
По названию можно догадаться, что это комбинация imphash и fuzzyhash. Если раньше, два файла с почти одинаковой таблицой импорта, имели разные imphash, то теперь сравниваются куски этой таблицы (fuzzyhash). То есть, вычисляется процент схожести одной импорт таблицы с другой. Данный подход убирает минусы оригинального алогритма и намного лучше выявляет схожесть.
Придумали этот способ в JPCERT. Статья Classifying Malware using Import API and Fuzzy Hashing
Еще более улучшенный алгоритм impfuzzyhash от Trend Micro, под название Call Graph Pattern, при котором сравниваются хэши вершин графа вызовов функций