
cat _posts/translations/2021-06-13-intro-minifilters.md
13 June 2021Введение в стандартные и изолирующие мини-фильтры
Все что выделено курсивом в тексте добавлено переводчиком и отсутствует в оригинальной статье!
Концепция драйвера-фильтра является одной из самых мощных архитектурных особенностей подсистемы ввода/вывода Windows. Использование таких драйверов может повысить функциональность существующего устройства и не требует внесения изменений в оригинальный драйвер устройства.
Драйверы-фильтры могут работать на разных уровнях Windows. Например, есть стандартные драйверы-фильтры, поставляемые с Windows, на уровне томов, которые обеспечивают функциональность создания снимков тома (для целей резервного копирования), а также опциональное шифрование всего тома (для Windows Bitlocker). Существуют также драйверы-фильтры от производителей устройств, например для мыши или клавиатуры, которые добавляют поддержку специфичных для моделей кнопок.
Одно из самых распространенных мест для применения фильтра в Windows - файловая система. Фильтры файловой системы перехватывают операции ввода-вывода (из приложений и самой системы) до того, как они будут выполнены в файловой системе. Это позволяет осуществлять мониторинг, перехват, управление, манипуляцию, и даже прием/отклонение операций ввода-вывода до того, как их увидит файловая система. Тип фильтра файловой системы знакомый большинству - это антивирусный фильтр. Этот фильтр (или, что бывает гораздо чаще, соответствующий сервис в пользовательском пространстве) обычно перехватывает операции открытия файла, приостанавливает их и сканирует открываемый файл на предмет вредоносности. Если файл определяется как вирус, операция открытия может быть отменена. Если же нет, открытие файла происходит успешно.
Фильтры файловой системы могут использоваться для разных целей - от антивирусного сканирования, как уже было описано, до отслеживания/управления лицензиями на ПО, от аудита и отслеживания изменений в файлах, до прозрачного шифрования и расшифрования данных. Эти фильтры могут использоваться и для менее очевидных целей. Например, возможность видеть какие файлы были созданы или изменены, используется в ПО для резервного копирования и системах иерархического хранения данных. Благодаря способности перенаправлять запросы к файлам, можно сделать так, чтобы файл в облаке, выглядел локальным.
Модель мини-фильтров файловой системы была впервые представлена в Windows XP SP2 и стала предпочтительным механизмом фильтрации . И неспроста, данная модель является отличной основой для разработки драйверов файловой системы. С хорошей документацией и кучей примеров на Github, многие разработчики получили возможность разрабатывать мини-фильтры файловой системы.
Данная статья описывает базовую концепцию мини-фильтров файловой системы Windows. Также она описывает их типы: стандартные мини-фильтры и изолирующие мини-фильтры. В заключение, дано объяснение тому, почему разработка изолирующих мини-фильтров сложнее, чем разработка стандартных.
Стандартные мини-фильтры vs. изолирующие мини-фильтры
Стандартные мини-фильтры
Стандартный мини-фильтр - это драйвер файловой системы Windows, который осуществляет мониторинг/отслеживание данных файловой системы. Практически все антивирусные сканеры являются стандартными мини-фильтрами.
Изолирующие мини-фильтры
Изолирующий мини-фильтр - это драйвер файловой системы Windows, который разделяет отображаемые и реальные данные файла. Типичный пример - фильтр шифрования/расшифрования. Изолирующие мини-фильтры используют концепцию “тот же самый стек” и соотносят секции кэша с различными представлениями данных файла.
Подробнее про стек можно прочитать тут
Менеджер фильтров и уникальные идентификаторы фильтров (Altitudes)
Фильтр файловой системы обязан иметь уникальный идентификатор, называемый altitude, который определяет позицию по отношению к другим фильтрам в стеке файловой системы. **altitude **= уникальный идентификатор (фильтра).
Основой модели мини-фильтров файловой системы является менеджер фильтров (стандартный Windows компонент). Менеджер фильтров реализован в виде устаревшего фильтра файловой системы и фильтрует все экземпляры файловой системы. Так как у экземпляра файловой системы могут существовать несколько фильтров (стандартная комплектация Windows включает в себя не менее девяти стандартных мини-фильтров!), менеджер фильтров предоставляет системе набор уникальных идентификаторов, которые позволяют разработчикам понять, в какое место, в иерархии фильтров, должен быть установлен их мини-фильтр. (смотрите рисунок 1)
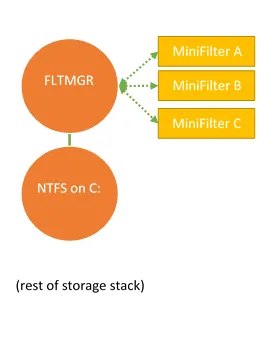
Рисунок 1 - менеджер фильтров с тремя мини-фильтрами файловой системы
На рисунке 1, вы видите менеджер фильтров Windows (FLTMGR), который осуществляет фильтрацию для экземпляра файловой системы NTFS, смонтированной как диск С. Менеджер фильтров имеет три загруженных мини-фильтра файловой системы: мини-фильтр А, мини-фильтр B, мини-фильтр С. Очередность фильтров не случайна (А над B, B над C). Более того, она зависит от уникального идентификатора присвоенного каждому мини-фильтру.
Уникальный идентификатор (Altitude) - это важный атрибут фильтров файловой системы, так как от него могут зависеть критические операции. Например, представьте два мини-фильтра, которые могут быть установлены для условной файловой системы: антивирусный мини-фильтр и мини-фильтр прозрачного шифрования данных. Чтобы антивирусный мини-фильтр выполнял свою работу, ему нужен доступ к расшифрованному содержимому файла. Поэтому, антивирусный мини-фильтр должен иметь более “высокий” уникальный идентификатор, чем мини-фильтр шифрования.
Функции обратного вызова (callbacks) мини-фильтров
Когда мини-фильтр регистрируется менеджером фильтров, помимо прочего, он может выбрать получать ли функции обратного вызова PreOperation/PostOperation для определенных операций ввода-вывода.
Функции обратного вызова PreOperation - вызываются перед каждой операцией ввода-вывода указанного типа, которые выполняются в фильтруемой файловой системе.
Функции обратного вызова PostOperation - вызываются после того, как файловая система (и любой мини-фильтр “ниже”) обработала операцию ввода-вывода определенного типа.
Поддержка функций обратного вызова менеджером фильтров очень хорошо продумана. Например, когда мини-фильтр получает функцию PreOperation, он может:
- Завершить операцию полностью. В итоге мини-фильтры с меньшими уникальными идентификаторами (если есть), и даже соответствующая файловая система, не увидят эту операцию ввода-вывода.
- Завершить операцию, передать ее мини-фильтру с меньшим уникальным идентификатором (если есть) и соответствующей файловой системе, и выполнить функцию PostOperation, когда операция завершится.
- Завершить операцию, передать ее мини-фильтру с меньшим уникальным идентификатором (если есть) и соответствующей файловой системе, и НЕ выполнить функцию PostOperation, когда операция завершится.
- Вернуть статус выполнения операции. В этом случае, мини-фильтр проинформирует менеджер фильтров позже о состоянии операции, необходимости обращения к базовым сущностям и требуется ли выполнение функции PostOperation.
Внутри своих функций обратного вызова PreOperation/PostOperation , мини-фильтр может выполнять практические любые операции, включая просмотр/модификацию данных. Таким образом, мини-фильтру необходимо понимать семантику этих операций.
Win32 API vs Native Windows API
Фреймворк менеджера фильтров для написания мини-фильтров имеет настолько большие возможности, что легко вводит в заблуждение разработчиков касательно фильтрации файловых систем. Суть в том, что разработка мини-фильтров может быть простой, но также может очень быстро стать удивительно запутанной.
Несмотря на всю мощь модели менеджера фильтров, мир файловых систем Windows сам по себе очень сложен. Некоторая часть этой сложности связана с тем, что Win32 API может сильно отличаться от нативного Windows API, который в действительности используется в подсистеме ввода-вывода. Простой пример, который мы часто встречаем в OSR _(компания, написавшая эту статью) _- это Win32 API CopyFile. Разработчики часто удивляются тому, что не существует нативного аналога этой функции. Вместо этого, внутри, **CopyFile **открывает файл-источник, открывает целевой файл, и если обе операции успешны, начинает серию операций чтения из файла-источника и запись в целевой файл, пока файл не будет скопирован. Файл-источник и целевой файл затем закрываются.
Чуть более интересный пример - это Win32 функция DeleteFile. Если вы не разработчик файловой системы, вы наверняка думаете “Разве удаление может быть сложным? Вы просто… удаляете файл, верно?”. Только не в Windows. Нативный Windows API на самом деле не имеет специальной операции удаления. Вместо этого, намерение удалить файл отражается операцией Set Information (ZwSetInformationFile
) и заполнением структуры FILE_DISPOSITION_INFORMATION. Это позволяет вызывающей функции указать хочет ли она удалить файл, после закрытия. Здесь важно заметить, что файл на самом деле не удаляется, пока не будет закрыт последний handle файла. Это означает, что приложение может открыть файл и вызвать Win32 DeleteFile API, но это на самом деле не удалит его. Даже если приложение пытается несколько раз закрыть файл, это все еще не гарантирует удаление. Представьте, что может случиться, если другое приложение откроет наш файл. Оно также может пометить файл на удаление. Если после этого наше приложение запросит удаление файла по закрытию, а другое приложение сделает обратное, файл не будет удален. И да такое случается.
Взаимодействие с системой виртуальной памяти
Другой источник сложностей для мини-фильтров файловой системы связан с тесным взаимодействием между файловой системой, Windows Cache Manager и Windows Memory Manager (далее - менеджер кэша и менеджер памяти). Все мы знаем, что когда мы вызываем ReadFile, данные считываются из файла, на который указывает handle. Большинство также знают, по крайней мере в общих чертах, что в этом участвует кэширование. Поэтому, вызов ReadFile не всегда означает чтение данных напрямую из файла.
Интересно, что за исключением тех случаев, когда файл открывается явно без кэширования, файловые системы обычно очень мало что делают для обработки вызовов ReadFile из приложения, не считая обращения к менеджеру кэша. По запросу файловой системы менеджер кэша копирует данные из области кэша, связанной с открытым экземпляром этого файла, в буфер данных приложения. Это показано на рисунке 2.
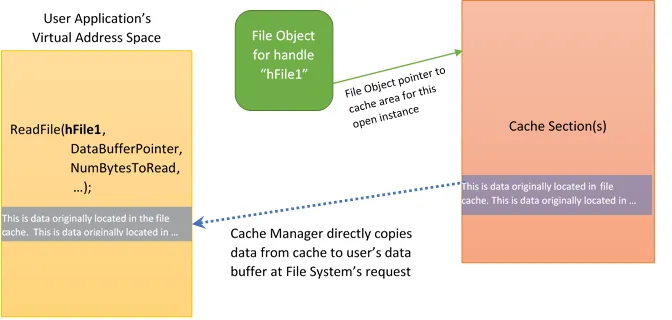
На рисунке 2 файловая система обращается к менеджеру кэша для обработки запроса приложения на чтение файла (ReadFile). Файловая система находит открытый экземпляр файла, к которому осуществляется доступ, по соответствующему handle (аргумент ReadFile). Handle “hFile1” относится к файловому объекту, который используется менеджером кэша для определения местоположения секций с кэшированными данными, являющихся частью кэша файловой системы.
Интересно, что данные, хранящиеся в кэше, считываются в память с диска менеджером памяти Windows с помощью обработки ошибок страниц памяти (page fault). Операция чтения страниц памяти также проходит через файловую систему.
Разумеется, мини-фильтры файловой системы могут быть задействованы в обработке операций чтения и записи, как из приложений, так и из менеджера памяти.
Упрощаем: Стандартные Мини-фильтры
Стандартные мини-фильтры являются самым распространенным типом мини-фильтров для мониторинга и логирования различных операций на уровне файловой системы. Некоторые мини-фильтры, такие как антивирусные сканеры, могут даже разрешать или запрещать определенные операции. Стандартные мини-фильтры не используются для изменения представления или размера данных файла, который они фильтруют. Мы называем их стандартными, потому что они составляют большинство существующих мини-фильтров файловой системы.
Основные трудности, с которыми сталкиваются разработчики стандартных мини-фильтров:
- Правильное понимание и взаимодействие с семантикой подсистемы ввода-вывода Windows
- Сохранение поведения всех родных операций файловой системы, даже непонятных или не особо важных для реализуемого функционала
Конечно, эти трудности являются дополнением к основным проблемам, присущим написанию любого драйвера режима ядра Windows.
Для преодоления первой из этих проблем просто требуется время и опыт. Существует множество примеров, предоставленных компанией Microsoft, которые можно использовать в качестве отправной точки. Документация по написанию базовых мини-фильтров файловой системы на удивление хороша, если предположить, что вы потратите время на ее прочтение и понимание. Есть также хорошие интернет-ресурсы, такие как наш список NTFSD, которые могут помочь, отвечая на вопросы, которые у вас могут возникнуть на этом пути. Я также должен отметить, что с января 2018 года мы будем проводить семинар по написанию стандартных мини-фильтров.
Сложность второго пункта во многом зависит от типа мини-фильтра. Разработка будет проще, если ваши операции и логика фильтрации будут простыми. Типичная ошибка - пытаться фильтровать ненужные для вас операции ввода-вывода. Тесты HLK для мини-фильтров файловой системы будут очень полезны для оценки вашего успеха в сохранении поведения фильтруемых файловых систем. Обязательно воспользуетесь ими!
Встреча с проблемами при написании стандартного мини-фильтр - это норма.
Экспоненциально сложнее: изолирующие мини-фильтры
Гораздо менее распространенным типом мини-фильтров являются изолирующие мини-фильтры. Изолирующие фильтры отделяют (или “изолируют”) представление данных файла от фактических данных, хранящихся в файловой системе. Разработка такого мини-фильтра обычно так же сложна, как и разработка стандартной файловой системы Windows, поскольку она подразумевает прямое и тесное взаимодействие между вашим мини-фильтром, менеджером кэша и менеджером памяти. На самом деле, некоторые опытные разработчики считают разработку изолирующих мини-фильтров еще более сложной, чем разработка файловой системы, потому что вам фактически приходится “подгонять” реализацию файловой системы Windows под API менеджера фильтра. Таким образом, в дополнение к проблемам, с которыми сталкиваются разработчики стандартных мини-фильтров, разработчики изолирующих мини-фильтров занимаются множеством значительно более сложных вопросов.
Чтобы проиллюстрировать, что мы имеем в виду под “отделением представления данных файла от реальных данных”, рассмотрим изолирующий мини-фильтр, реализующий прозрачное шифрование/расшифрование данных. Приложение открывает файл и вызывает ReadFile. Файл хранится на диске в зашифрованном виде. Задача мини-фильтра в данном случае заключается в прозрачном расшифровании данных, предоставляемых приложению. Общая схема процесса показана на рисунке 3.
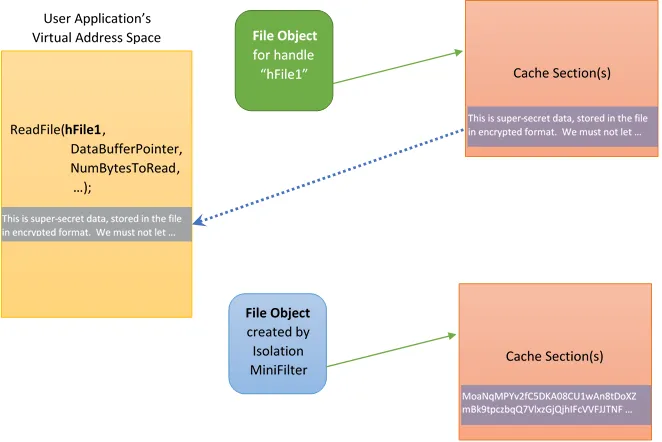
Рисунок 3 - изолирующий мини-фильтр
На Рисунке 3 показаны два файловых объекта, которые представляют один и тот же файл. Файловый объект сверху (зеленым цветом) является открытым экземпляром, связанным с приложением. Этот файловый объект является представлением файла для приложения. Обратите внимание, что секция кэша, на который ссылается файловый объект, содержит расшифрованные данные. Данные были помещены в кэш изолирующим фильтром, работающим совместно с диспетчером кэша.
Нижний файловый объект (синим цветом) был создан изолирующим мини-фильтром и является представлением файла для мини-фильтра (и соответствующей файловой системы). Обратите внимание, что данные в секции кэша для этого файлового объекта зашифрованы. Изолирующий мини-фильтр использует его для взаимодействия с файловой системой.
Таким образом, когда пользовательское приложение вызывает ReadFile, изолирующий мини-фильтр получает этот запрос (в рамках функции обратного вызова PreOperation, обсуждавшейся ранее) и взаимодействует с менеджером кэша, чтобы заполнить кэш данными. При обработке последующих операций чтения (производимых менеджером памяти для удовлетворения запросов менеджера кэша по получению данных для кэша) изолирующий мини-фильтр инициирует операцию **ReadFile **ссылаясь на нижний (синий) файловый объект. Файловая система, работающая с диспетчером кэша, выполняет этот запрос и помещает данные в указанную секцию кэша.
Все становится еще сложнее, если учесть, что большинство прозрачных систем шифрования данных используют метаданные в заголовке файла (для хранения ключей или прав доступа). Таким образом, смещение файла, используемое приложением для операций чтения, может отличаться от смещения, которое изолирующий фильтр должен использовать при доступе к файлу, хранящемуся на диске.
Но обычно все гораздо сложнее того, что мы обсуждали до сих пор. Мини-фильтр для шифрования/расшифрования определяет для каждого отдельного приложения, выполняющего операцию чтения, какие именно данные, зашифрованные или расшифрованные, оно должно получить. Например, изолирующий мини-фильтр может автоматически расшифровывать данные из зашифрованного документа при обращении от Microsoft Word. В то же время, когда к нему идет обращение из приложения резервного копирования, изолирующий мини-фильтр может предоставить исходное, зашифрованное содержимое файла. Что еще более интересно, хорошо продуманный изолирующий мини-фильтр может предоставлять два разных представления файла, зашифрованное и расшифрованное, для различных приложений, читающих файл одновременно. А что произойдет, если одно из этих приложений записывает данные в файл, в то время как другое будет иметь доступ к другому представлению файла? Скажем так, произойдет много интересного.
Изолирующие мини-фильтры: Не только шифрование
Необходимо дополнить, что модель изолирующих мини-фильтров используется не только для систем шифрования/расшифрования данных. Она используется если:
- Существует разница между представлением данных файла в приложении и в файловой системе.
- Существует разница между представлением данных файла в приложении и их реальным расположением.
- Разным приложениям необходимо иметь отдельное представление одних и тех же данных находящихся в файловой системе
Например, рассмотрим изолирующий мини-фильтр для отслеживания изменений и версионирования. Один процесс Word может активно редактировать последнюю версию файла, в то время как другой процесс Word (возможно, запущенный другим пользователем) может активно редактировать более старую версию файла.
Или рассмотрим файл, который хранится в облаке и обрабатывается небольшими порциями, в зависимости от того, как к нему обращаются. Приложения могут видеть этот файл, как будто он находится полностью в локальной файловой системе. Тем не менее, изолирующий мини-фильтр может осуществлять доступ и обратное заполнение данных из удаленного хранилища по мере необходимости.
Какой можно сделать вывод из всего этого?
Модель мини-фильтров в Windows является гибкой и чрезвычайно мощной. Имея достаточно времени и опыта, большинство разработчиков смогут разработать стандартный мини-фильтр. Эти фильтры отслеживают операции с файлами или могут разграничивать права доступа к файлам в файловой системе. Основные проблемы, связанные с разработкой стандартных мини-фильтров, заключаются в понимании семантики файловых систем Windows и предоставлении приложениям всех функциональных возможностей файловой системы. Обе эти задачи поддаются решению и могут быть решены без огромного опыта работы с файловой системой Windows.
В отличие от стандартных мини-фильтров, существуют изолирующие мини-фильтры. Эти мини-фильтры позволяют приложениям получать свое представление данных, отличное от реальных. Разработка изолирующих мини-фильтров больше похожа на разработку целой файловой системы Windows, чем на разработку стандартных мини-фильтров, поскольку она требует тесного взаимодействия с менеджером кэша и менеджером памяти. Разработка изолирующих мини-фильтров вряд ли является задачей, которая может быть успешно решена большинством разработчиков, которые не стремятся стать экспертами по файловой системе Windows.